
Data Integration is an essential activity that allows an organization to combine data from disparate sources into a unified version for a variety of uses. Proper data integration starts at architecture, includes understanding requirements and the data, and ends with trusted valid results.
Introduction
Data integration is the collection of technical and business processes used to combine data from disparate sources into meaningful and valuable information. Most organizations have many separate applications and systems that contain large amounts of data, which could be combined in various ways for business intelligence and analysis, improved operations, and other activities. Data integration is a complex initiative, one that requires attention to enterprise architecture and its components: data architecture, application architecture, technical / infrastructure architecture; metadata management, master and reference data management, data quality management , and data governance . Many organizations consider data integration to be only a part of a data warehouse effort, when actually it is a valuable function in data management and technical design in its own right.
Data Integration Concepts
Data integration involves combining data, either whole sets of data or selected portions based on business requirements, from more than one source into a specific target, to provide a unified view of the combined data.
Many data integration projects are part of a data warehouse initiative, since the definition of a data warehouse includes the collection of data from multiple sources. According to much research over many years, approximately 80% of the effort expended in a data warehouse project concerns the mapping for data, and the extraction/transformation/cleansing/loading (ETL) that is collectively known as data integration.
The data integration process covers several distinct functions:
Source-Target Mapping
Source-Target Mapping is the process that defines the metadata for the data elements for each file / table for every source system involved in the data integration effort, aligned to the corresponding attribute in the target application table. It contains the relevant metadata for the chosen data to be included in the ETL process, and therefore can be considered as the blueprint for the ETL design.
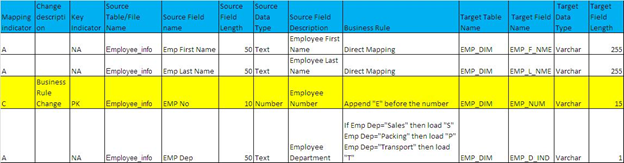
Extraction-Transformation-Loading (ETL)
Drawn from the data warehousing domain, extraction/transformation/loading are the processes that take the data from the sources, transform it from its current state into a unified version, and load the unified version to the target application’s database. To improve data quality, this set of processes includes data cleansing, which are the routines that parse the data against parameters set by subject matter experts for accuracy, completeness, validity, and other data quality dimensions (characteristics). Cleansing includes the application of data unification rules (e.g., converting addresses to standard format, replacing null values with N/A, etc.)
The extraction step should be designed so that it does not affect the source system negatively for performance, response time or encounter any form of lock (database, table, row, etc.). The transform step applies a set of rules to transform the data from the source format to the desired target format, applying any required connections to other data in the process, and validating any additional business / technical rules. The load step places the cleansed and transformed data into the target database as smoothly and quickly as possible, while maintaining all referential integrity in the database.
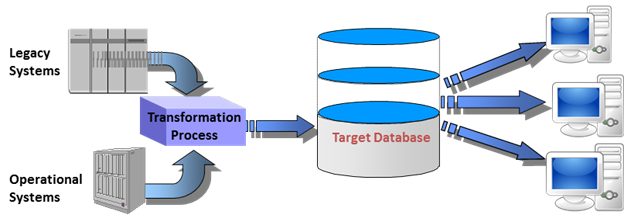
Figure 1: Non-Data Warehouse Data Integration Example
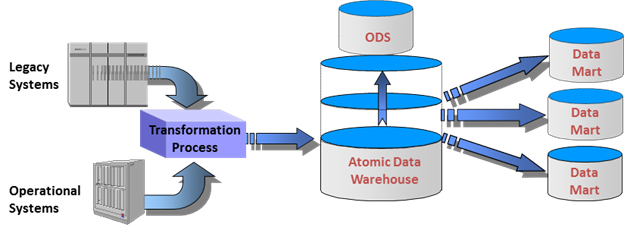
Figure 2: Data Warehouse Data Integration Example
Data Integration Cycle
The typical data integration process, commonly called an ETL Cycle, has the following steps:
- Cycle initiation
- Build source-to-target mapping for business area
- Extract (from sources)
- Validate process and data
- Transform (clean, apply business rules, check for data integrity, create aggregates or disaggregates, perform any conformance processes)
- Stage (load into staging tables)
- Publish (to target tables)
- Prepare audit reports
- Archive
- Close out, prepare for next cycle
Each of these steps is a process and would include a set of activities that may involve a variety of people, technologies, and tasks. Neglecting any step listed would mean the cycle was not fulfilled and that the ETL process as a whole was not completed, reducing the effectiveness of data integration.
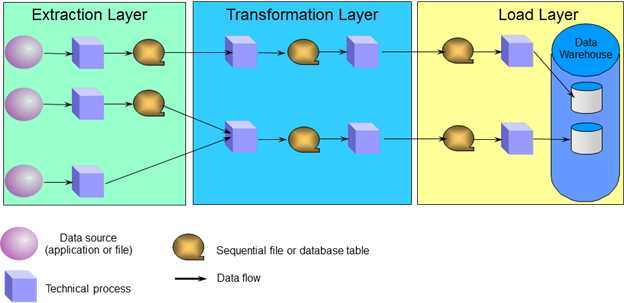
Business Rules as Part of Data Integration
One of the tasks in the Transform step of the ETL Cycle is to “apply business rules.” Business rules are abstractions of the policies and practices of a business organization. They are essential metadata for any data integration effort, since they specify the actions that must occur (or not occur) to the data in a record/table/file/database under a set of conditions. Applying the business rules to the data set is an iterative process, which includes reviewing the existing business rule documentation, validating assumptions, applying the rules to the data set and confirming the act, and documenting the relevant metadata for the data associated with each business rule. It is important for all data integration efforts to include business rules as part of the project since they provide valuable information concerning the operations of organization and its data in business and technical contexts.
Data Quality Challenges in Data Integration
Poor data quality (perceived or real) causes distrust from business users when using data in data warehouses and data integration projects. This lack of trust may cause customers to look for analytical solutions elsewhere. Additionally, poor data quality leads to poor decisions and improved costs due to re-work, missed opportunities, error corrections, etc. Almost half of all firms do not have a data quality plan, according to a 2010 Gartner Group study. This lack can severely affect the performance of all data integration efforts, and produce erroneous mistakes in the integrated data sets, leading to poor decisions or ineffective operations. Ensuring that data quality management is part of all data integration projects is essential for success and optimal results.
Data Integration Audit Processes
Data integration processes produce metadata that must be recorded and analyzed. It is important to study this metadata to understand the performance of the integration processes for quality control and improvement. Metadata from DBMS system tables and from schema design tools is easy to capture, but probably composes only 25 percent of the metadata needed to understand and control the data integration process. Another 25 percent of the metadata is generated by the cleansing step.
The biggest metadata challenge for the data integration team is developing and storing process-flow information. In ETL tool suites, this process-flow metadata is maintained automatically; however, if the application is written specifically, the project must implement a central repository of process flow metadata.
Every data integration audit process requires the creation of several tables and programs. Following is an example of an important table that records the metadata in the data integration process.
| Column Name | Description |
| JobNumber | The unique number of the job that this step is associated with. |
| StepSeqNumber | The step number within the object that executed the unit of work |
| StepDescription | A description of the step. For example, “Inserted records into tblA.” |
| Object | The name of the object. For example, the name of a stored procedure or package that accomplishes the step. |
| NumberRecords | The number of records affected by the step. |
| MinThreshRecords | The minimum “acceptable” number of records affected by the step. |
| MaxThreshRecords | The maximum “acceptable” number of records affected by the step. |
| MinThreshTime | The minimum “acceptable” execution time for the step. |
| MaxThreshTime | The maximum “acceptable” execution time for the step. |
| CreateDate | The date and time the record was created. |
| StepNumber | A unique value assigned to the record, generally an identity column. |
Table 1: AdminStepMaster
Many ETL jobs are multi-step, complicated transformations. It is important to record metadata that tracks the successful completion of an operation, when it happened and how many rows it processed. This information should be stored for every step in an ETL job.
Data Integration Testing
Testing the data integration process, and the data that has been moved, is a crucial component of the effort. There are three phases of any test process:
- Unit testing – occurs during and after development, performed by the developer and the systems analyst in the development environment
- Quality Assurance testing (QA) – occurs by a separate group in a separate environment mirroring production
- User Acceptance Testing (UAT) – occurs by the user group in a separate controlled environment created from the QA environment; letting users have a hands-on look at the data to ensure processes are running as expected
At the end of UAT, the test manager should obtain sign-off from the user representative. Once sign-off has been received, the data integration application is ready to move to production.
When testing new ETL processes, it is important to have users test for known data issues and source system anomalies. Not only will this validate the project’s efforts; exposure to the clean data will excite users and make them eager to use the new data source. Clean data can create some positive effects. Users will communicate the success of the data integration project, and this will lead to additional requests for integrated data that is based on a confirmed approach, governed by best practices, and filled with high quality data that adheres to organizational business rules.
General Data Integration Challenges
Data integration processes can involve considerable complexity, and significant operational problems can occur with improperly designed data integration applications. Following best practices in enterprise application / integration / data architecture can alleviate or eliminate many of the issues that are encountered by poorly designed data integration systems.
The range of data values or the level of data quality in an operational system may not meet the expectations of designers at the time validation and transformation rules are specified. Documenting business rules, including data quality expectations, can reduce the issues that arise due to data anomalies. Data profiling of a source during data analysis can identify the data conditions that must be managed by transformation rules and their specifications. Doing so will lead to changes to validation rules, explicitly and implicitly, that are implemented in the ETL process.
Data warehouses, a major form of data integration, typically are assembled from a variety of data sources with different formats and purposes. Therefore, ETL is the key process to bring all the data together in a standard, homogeneous environment. Without error-proof data integration (ETL), the data warehouse will not succeed.
Data integration architects should establish the scalability of any data integration process across the lifetime of its usage. This includes understanding the volumes of data that will be processed according to service level agreements. The time available to extract from each source system may change, which may mean the same amount of data may have to be processed in less time, or there may be additional sources to process in the same window. Data integration scalability is essential for a successful system.
Conclusion
Data integration is a critical process that allows an organization to combine data from disparate sources into a unified version for a variety of uses. Not just for data warehousing, proper data integration starts at architecture, includes understanding requirements and the data, and ends with trusted valid results. With data integration informed by best practices, any organization can achieve collated data that becomes information to improve operations and make decisions.

